Team effort: the North American Multi-Model Ensemble
As our frequent visitors will know, I usually write the top-of-the-month ENSO Blog post. That post covers the outlook for ENSO—the El Niño/Southern Oscillation, aka the entire El Niño/La Niña system. This post, however, is about my other favorite acronym: NMME, the North American Multi-Model Ensemble. It’s an important input to the ENSO outlook, and often pops up in the Blog—for example, Nat just included the NMME forecast for ENSO in the May update post.
Small acronym, big project
In a single sentence, the NMME is a seasonal prediction system that combines forecast information from state-of-the-art computer climate models currently running in the U.S. and Canada (1). Seasonal here means the monthly and three-month averages—e.g., the expected temperature averaged over June–August. The NMME has posted global forecasts early each month since August 2011 and informs NOAA’s official seasonal outlooks, while also providing the basis for hundreds of applied research projects.
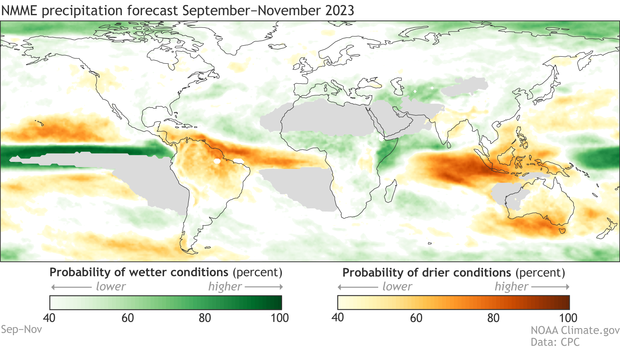
Example forecast from the NMME, made in early May 2023, for precipitation averaged over September–November 2023. Green colors show the probability of wetter-than-average conditions, while orange shows the chance of drier-than-average. The darker the color, the stronger the chance. Average is based on 1991–2020. Gray areas in the eastern Pacific, northern Africa and the Middle East, and western Australia indicate general areas that historically receive very little precipitation during September–November. Climate.gov figure from NMME data.
The magic of NMME is that, by combining information from several different models into a multi-model ensemble, it produces better forecasts overall than those from a single model (2). This is the same principle as asking a crowd of people to guess the number of jellybeans in a jar. Usually, each individual guess will be too low or too high, while the average of the guesses ends up closest to the real number.
In the case of climate models, they each have their own errors and biases, and averaging their forecasts into a multi-model ensemble cancels some of those out, leading to a more successful forecast. Errors and biases result from the inevitable simplifications we’re forced to make when trying to write a computer program to simulate the entire global system.
One example of this complexity is how a single thunderstorm can dump inches of rain in just a few minutes on your neighborhood, but right down the street, they remained dry. We use incredibly powerful computers to run climate models, but even so it’s difficult, if not impossible, to accurately resolve every minute and every square meter of the planet. Perhaps we’ll eventually develop a single model that can successfully predict global climate, but we’re not there yet!

For questions ranging from “How many jellybeans are in this jar?” to “Will El Niño develop later this year?” the average of multiple individual guesses usually ends up closer to the actual number than any single guess because the errors in individual guesses (or forecasts) cancel each other out. NOAA Climate.gov cartoon.
Team players
The groups that comprise the NMME are a bit of an alphabet soup. We have the National Aeronautics and Space Administration (NASA), Environment and Climate Change Canada (ECCC), and two groups from the National Oceanic and Atmospheric Administration (NOAA)—the National Centers for Environmental Prediction (NCEP) and the Geophysical Fluid Dynamics Lab (GFDL)—all contributing model forecasts. The University of Miami provides a model and leads the NMME research project. The International Research Institute for Climate and Society (IRI) hosts all the model data, while NOAA’s Climate Prediction Center (CPC) posts forecast images every month. All these groups work together to keep the NMME running smoothly and on time.
Speaking of time…
One of the most important aspects of the NMME is that it includes both real-time forecasts—predictions made early each month for the upcoming 12 months, much like the ENSO outlook—and an extensive research activity to improve seasonal prediction. The research enterprise is facilitated by the NMME requirement that all participating models provide not only real-time forecasts, but also retrospective forecasts that are run for the past, before the model started making real-time forecasts, going back to 1982, so that we have many years of data to examine (3).
This combo provides an important research-to-operations pipeline, where research projects can turn into real-time forecast products. One example of this is NOAA’s marine heatwave forecasts, which use NMME to predict warm ocean temperatures that can impact marine life. Another example, NASA’s Hydrological Forecast and Analysis System, provides seasonal drought forecasts for Africa and the Middle East, using NMME temperature and precipitation information. The NMME even contributes to forecasts for the environmental suitability of the Aedes mosquito, an important disease vector.
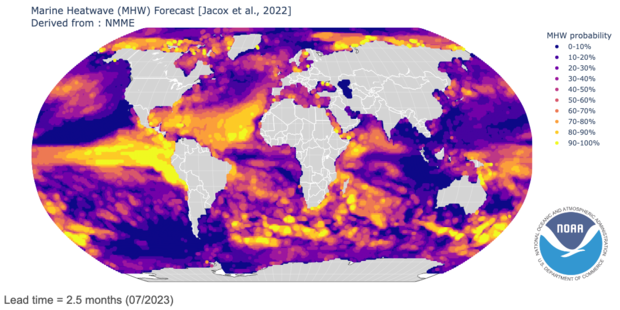
Sample marine heatwave forecast for July 2023, made in early May 2023, from NOAA’s Physical Sciences Laboratory. Yellow indicates higher chances of marine heatwaves, while purple indicates lower probabilities. Image provided by the NOAA Physical Sciences Laboratory, Boulder, Colorado.
The real-time/research combination is also a critical factor in driving seasonal prediction research and model development forward. When you can test a model in real-time and compare it to other models on the same playing field, you can make interesting discoveries. An example of this is Michelle’s recent work investigating the climate-change trend in the tropical Pacific and comparing the observed trend over the past 40 years to the trends in the NMME models. The observed and model trends are markedly different, which has a lot of implications for both ENSO prediction and climate change. Lots more on that topic in this recent post.
Progress
Climate models are immensely complicated and take a lot of time and resources to develop. Sometimes, the gaps between model upgrades can stretch into a decade and beyond. Since the NMME has several different participating models, whenever a new or updated model is available from one of the modeling centers, it’s swapped into the NMME, allowing the system as a whole to take advantage of upgrades as soon as possible. Since NMME started 12 years ago, all but one model has been replaced with newer versions, some more than once.
This continual updating process has contributed to gradual improvement, particularly in forecasts of land and ocean surface temperature. However, prediction of precipitation has remained stubbornly difficult, barely budging with model upgrades. While this is pretty disappointing—we’d really like to have better prediction of seasonal rain and snow!—it does tell us something useful: we likely can’t expect incremental progress for precipitation with our current models. In order to achieve better precipitation forecasts we may need more computationally intense, higher-resolution models, and/or some innovative techniques such as artificial intelligence. In the meantime, multi-model systems such as the NMME provide substantially better precipitation forecasts than any single model (4).
Buddy check
To bring this post home, I’ll refer back to an ENSO Blog post written during the decline of the last strong El Niño event in spring 2016. At that time, almost all signs were indicating that neutral conditions would shortly return (which they did!). However, the NMME had a couple of rogue models that showed a continuing El Niño, in sharp contrast to the other 5 models. Some investigation, spurred by the ENSO forecast team, revealed that a bug was causing these two odd forecasts. A fix was found, and the models returned to reality. We all go a little off the rails sometimes, and it’s good to have friends to keep us on track!
I hope you’ve enjoyed your brief tour of the NMME. A whole lot more info is available in a recent paper authored by me, Michelle, and a few other representatives of the NMME team, or feel free to pose questions in the comments.
Footnotes
- “State-of-the-art” in this case refers to global, coupled dynamical models. Global in that they produce forecast information for the entire planet, as opposed to specific regions. Coupled models mean that the atmosphere, ocean, land, and cryosphere all interact in the model. And dynamical means that the model uses complex physical equations to predict the future. All these models are initialized: we provide them a picture of current ocean, atmospheric, and land conditions from which to start.
- Occasionally, a single model will beat the multi-model ensemble for a specific location, time, or variable (temperature, precipitation, etc.). However, for the best forecasts overall, many, many research studies examining lots of different multi-model ensembles have found that multi-model is the way to go. There are some strategies that look at how well a model did in the past (see the next footnote) and give that model more weight for a certain location or variable in future forecasts. This is an active area of research, but so far has not given us a clear answer that it results in better predictions.
-
To create a retrospective forecast, the model is run for some time before the model was developed. So, if a model starts making real-time forecasts in 2011, we would run it for the years 1981–2010 to create a database of “forecasts” for a time that has already happened. For example, we initialize the model on January 1, 1982 and get a “forecast” for 1982. Then, since we know what happened in 1982, we can evaluate how close the model forecast was to reality. The language is confusing, because we use the word “forecast” for both when we don’t know the outcome (the future) and when we do (the past), just appending the word “retrospective” in the latter case. Retrospective forecasts are also called “hindcasts” or “reforecasts.”
For seasonal prediction, the model is usually run in retrospective mode to create at least 30 years of these forecasts for the past. This allows us to see if it has consistent biases, such as consistently making too-warm temperature predictions, and remove these biases from future forecasts. These retrospective forecast datasets, are usually made once, before a model goes live with real-time forecasts. Running the retrospective forecasts, which is computationally intensive and takes a lot of time, is one of the major hurdles to a quick development and implementation of a new model. However, it’s critical to understanding how the model works and creating better predictions for the future.
Finally, sometimes researchers will re-run a model for an individual forecast, but make changes to the model so we can understand the earth system better, why a forecast went wrong, how unusual an event was, and so on. An example of this could be re-running the model after a strong El Niño event, but removing the global warming trend, so we can ask questions like “what impact did climate change have on the outcome?” These are also “retrospective,” but when we use that term in the context of a modeling system, we mean the 30-year set of predictions for the past.
- You may be asking “better? Better how?” There are a lot of ways to evaluate a forecast, especially in the case of a probabilistic forecast like the NMME map I show above. Here, again, the retrospective forecasts for the past 30 or 40 years come in handy. We can select a statistic and compare how well each individual model does over many forecasts, and then combine models into a multi-model ensemble and see how well that combination does. I’ve done a lot of these studies and have yet to find a statistic where a single model out-performs the multi-model ensemble!
Comments
Reminder about comments
Hi readers! Here's my standard reminder about comments:
Forecasting and AI
You mention that precipitation in particular has been resistant to the kind of incremental but real improvements in forecasting seen in other aspects of climate, and suggest it probably won't improve without some sort of fundamental shift in skill. You mentioned AI in this context. Are researchers you know of experimenting with AI? Thanks
Quite a few well-known…
Quite a few well-known climate scientists are testing machine learning techniques as applied to prediction. I don't know of specific ones who are examining precipitation prediction, but I'm certain they exist! Maybe some can weigh in here.
Machine learning
Consider the potential implications of LLM variants of machine learning and neural nets, which are able to bring in a wider context of knowledge to a signal processing problem with a complicated fingerprint, such as ENSO or QBO The ML model doesn’t care that it’s going outside the scope of accepted tribal knowledge, it will just crank away and present what the fingerprint matches might be. Better predictions will be a result.
Great Introduction
Very well written introduction to a more advance way of forecasting long term weather / climate. Improvement is always there, and I think that will come with more implications of artificial intelligence.
When we know for sure that an El Nino has actually formed in the Tropical Pacific and the strength of the event ?
Our decision tree for El…
Our decision tree for El Nino onset is provided here: https://www.climate.gov/news-features/blogs/may-2023-enso-update-el-niño-knocking-door
We update the ENSO prediction on the 2nd Thursday of each month (so next one is June 8th).
AI
It seems to me that the whole current state of forecast modeling and ensemble modeling is by nature an existing form of AI.
It depends on your…
It depends on your definition of AI! Many think of AI as involving Neural network approaches. Some weather models have already been created that use NN: https://agupubs.onlinelibrary.wiley.com/doi/full/10.1029/2020MS002109
AI and Machine learning
The reason that neural nets work is that they work on non-linear aspects of the fluid dynamics physics. If linear equations occupy a space of solutions, nonlinear formulations offer infinitely many more possibilities.
Add new comment